
Resumo — “Clientes que compraram este item também compraram…”. Esta frase, popularizada pela Amazon, é o resultado de um dos algoritmos de grafos mais elegantes e impactantes do e-commerce: o Item-Item Collaborative Filtering (CF). Em vez de tentar encontrar usuários “gêmeos” (o que é lento e instável), a Amazon focou em calcular a similaridade entre os itens. A ideia é projetar o imenso grafo bipartido (usuário-item) em um novo grafo (item-item), onde as arestas representam a similaridade.
1. O Problema: Um Grafo Bipartido Instável
Como a maioria dos sistemas de recomendação, o problema da Amazon começa com um grafo bipartido, exatamente como vimos no nosso post sobre a Netflix.
- Nós do tipo A: Usuários.
- Nós do tipo B: Itens (produtos).
- Arestas: Interações (comprou, avaliou, clicou).
Uma abordagem inicial popular era o “User-User CF”: para me recomendar algo, o sistema primeiro encontrava “gêmeos” de gosto — outros usuários que compraram e avaliaram coisas de forma parecida comigo. O problema? Os gostos das pessoas mudam constantemente, e encontrar esses “gêmeos” em um grafo de milhões de usuários é computacionalmente caríssimo.
2. A Grande Virada: Focar nos Itens
A equipe da Amazon (liderada por Sarwar et al. em seu famoso paper de 2001) teve uma percepção fundamental: as relações entre os itens são muito mais estáveis do que as relações entre os usuários.
Um livro de “Teoria dos Grafos” será sempre similar a um livro de “Algoritmos”, independentemente de quem os compra. A solução, então, foi mudar a pergunta de “Quais usuários são parecidos com você?” para “Quais itens são parecidos com os que você já comprou?”.
Para isso, eles “projetaram” o grafo bipartido em um novo grafo, muito menor e mais estável: um grafo Item-Item.
3. Construindo o Grafo de Similaridade Item-Item
Neste novo grafo, os nós são apenas os Itens. A aresta entre dois itens (ex: Livro A 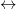
Mas como calcular essa similaridade? Olhando para os usuários que interagiram com ambos.
Imagine que cada item é um “vetor” onde cada posição corresponde a um usuário, e o valor é a nota que aquele usuário deu. Para saber se o Livro A e o Livro B são similares, o algoritmo compara seus vetores de avaliação.
Em termos técnicos, a métrica de similaridade mais comum é a Similaridade de Cosseno (Cosine Similarity):

Traduzindo a matemática: Esta equação trata os vetores de avaliação de dois itens (
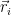

Outras métricas, como Adjusted Cosine ou Pearson Correlation, também são usadas para ajustar por bias (ex: usuários que só dão notas altas ou só notas baixas).
Uma vez que essa similaridade

4. Gerando Recomendações: Uma Soma Ponderada
Agora, a parte mágica e simples. Quando você (

- Ele olha para o seu histórico de compras e avaliações (os itens
- Para cada item
- Ele gera uma “pontuação” para cada item candidato



A fórmula de pontuação para um candidato

Traduzindo a matemática: A “pontuação” de um novo item


5. Desafios do Mundo Real: Recência e Cold-Start
Esse sistema é poderoso, mas tem dois desafios clássicos que a engenharia precisa resolver:
- Recência (Recency): Um livro lançado hoje não tem histórico de co-compra. Para evitar que o sistema só recomende itens antigos, as interações mais recentes (compras de ontem) devem ter um “peso” maior do que as do ano passado (usando uma função de decaimento temporal).
- Cold-Start (Item Novo): Um item novo não tem interações. Como calcular sua similaridade? A solução é um fallback para filtragem baseada em conteúdo. O sistema assume que o novo item é similar a outros itens que compartilham os mesmos atributos (mesma categoria, mesmo autor, mesmas palavras-chave na descrição).
6. Por que Item-Item Ainda é Relevante?
No mundo das GNNs e do Deep Learning, por que esse algoritmo de 2001 ainda é tão importante?
- Explicabilidade: É fácil de explicar. “Recomendamos X porque você comprou Y, e pessoas que compraram Y também compraram X.” Isso é muito mais claro do que “Recomendamos X porque o produto vetorial dos fatores latentes 3, 17 e 42 foi alto”.
- Escalabilidade: O grafo Item-Item é (relativamente) pequeno e estável. Ele pode ser pré-calculado e atualizado de forma incremental (só recalculando os itens afetados por novas compras) e armazenado em índices esparsos para consulta em milissegundos.
- Desempenho: É um baseline (ponto de comparação) extremamente difícil de bater. Muitas soluções complexas de deep learning falham em superá-lo em cenários do mundo real.
Conclusão
O Item-Item Collaborative Filtering da Amazon é uma das ideias mais fundamentais na história da recomendação. É um exemplo perfeito de modelagem de grafos: ele nos ensina que, às vezes, a melhor maneira de resolver um problema em um grafo complexo (o bipartido usuário-item) é projetá-lo em um grafo novo e mais simples (o item-item) que captura a essência da relação que realmente importa.
Referências
- Sarwar, B. et al. (2001). Item-based collaborative filtering recommendation algorithms. Proceedings of the 10th International Conference on World Wide Web (WWW).
- Herlocker, J. L. et al. (2004). Evaluating collaborative filtering recommender systems. ACM Transactions on Information Systems (TOIS).
Sobre o autor
Rener Menezes
Cofundador & CTO — FitBank
Rener Menezes é cofundador e CTO do FitBank, fintech brasileira de Banking-as-a-Service. Com mais de 25 anos de experiência projetando sistemas financeiros em larga escala, é bacharel em Sistemas de Informação e mestrando na Unifor, onde pesquisa Redes Neurais de Grafos e aprendizado por reforço para detecção de fraude. Interesses: sistemas distribuídos, infraestrutura de pagamentos e graph ML.
Links: LinkedIn · ORCID · contato@grafolab.ia.br
Deixe uma resposta