
Resumo — O recurso “Quem Seguir” (Who To Follow – WTF) do Twitter/X é um dos sistemas de recomendação de maior sucesso e influência da web. Ele resolve um problema clássico: como sugerir contas relevantes em um grafo social gigantesco e dinâmico? A fundação dessa solução não é um modelo de deep learning complexo, mas sim uma aplicação elegante de um algoritmo clássico de grafos: o Personalized PageRank (PPR). Este post explica a intuição, a modelagem e a engenharia por trás dessa ideia.
1. O Problema: Previsão de Arestas em um Grafo Dirigido
Quando você pensa em “recomendação”, talvez imagine sistemas como o da Netflix (usuários e itens). O desafio do Twitter é diferente. O Twitter é um grafo social dirigido:
- Nós: São as contas de usuário (você, seus amigos, empresas, celebridades).
- Arestas Dirigidas: São as relações de “seguir”. Uma aresta



O problema do “Quem Seguir” é, essencialmente, um problema de previsão de arestas (link prediction). O sistema precisa adivinhar: “Quais são as arestas

Uma abordagem ingênua, como sugerir as contas mais populares (com mais seguidores), falharia. Você não quer ver apenas celebridades e políticos; você quer encontrar pessoas relevantes para o seu círculo de interesses e conexões.
2. A Solução: O “Navegante Aleatório Pessoal”
A solução genial do Twitter foi adaptar o famoso algoritmo PageRank do Google. Lembre-se do PageRank clássico: ele simula um “navegante aleatório” que pula de página em página seguindo links, e a importância de uma página é a probabilidade desse navegante estar nela.
O Twitter adaptou isso para o Personalized PageRank (PPR).
Imagine um “navegante aleatório” que tem um “favorito”: você. O passeio dele funciona assim:
- Ele começa na sua conta.
- Ele dá um passo, seguindo aleatoriamente uma das pessoas que você segue (ex: ele “visita” a conta do Rener).
- Da conta do Rener, ele dá outro passo, seguindo alguém que o Rener segue (ex: ele “visita” a conta da Ana).
- A cada passo, ele tem uma escolha:
- Com probabilidade
- Com probabilidade
- Com probabilidade


Após rodar essa simulação por muito tempo, as contas onde esse “navegante pessoal” passou mais tempo são, por definição, as mais relevantes e “próximas” de você. O PPR é uma medida de proximidade e importância relativa ao seu nó no grafo, não uma medida de popularidade global.
Em termos técnicos, a equação do PageRank é sutilmente alterada. A equação clássica é:

No PageRank clássico do Google, o vetor de teleporte
Traduzindo a matemática: O score de uma conta (



3. Além do PPR: Refinando o Ranking
O PPR puro é a base, mas o sistema de produção (descrito no famoso paper de 2013) é um ensemble que usa outros sinais para refinar a lista:
- Fechamento Triádico: A ideia de que “o amigo do meu amigo é meu amigo”. O PPR captura isso muito bem. Se você segue o Rener, e o Rener segue a Ana, a Ana terá um score de PPR alto para você.
- Reciprocidade: A pessoa sugerida já te segue? Isso é um sinal forte.
- Popularidade Local: Quão popular é essa conta dentro do seu círculo de interesses, e não globalmente?
- Recência e Engajamento: A conta é ativa? Você interagiu com tópicos similares aos que ela posta?
4. O Desafio da Engenharia: Milissegundos
Calcular o PPR exato para centenas de milhões de usuários em tempo real é computacionalmente impossível. A engenharia por trás do “Quem Seguir” é tão impressionante quanto o algoritmo.
- Aproximação: O sistema não calcula o PPR exato. Ele usa aproximações rápidas, como simular um número finito de “caminhadas aleatórias” (Random Walks) a partir do seu nó para estimar os scores.
- Cálculo em Subgrafo: A caminhada aleatória não roda na web inteira, mas em um “subgrafo de interesse” ao seu redor.
- Cache Quente: Os resultados são pré-calculados e armazenados em sistemas de cache de alta velocidade, para que as sugestões possam ser entregues em milissegundos quando você acessa o site.
- Atualizações Incrementais: Quando você segue uma nova pessoa, seu “ponto de partida” muda. O sistema detecta isso e dispara o recálculo das suas sugestões de PPR, mantendo a lista atualizada.
5. Conclusão: A Lição do Twitter (X)
O caso do “Who To Follow” é uma aula magistral sobre o poder dos algoritmos de grafos “clássicos”. Ele demonstra que, para muitos problemas de recomendação em redes (como link prediction), uma modelagem de grafo inteligente (nós e arestas dirigidas) combinada com o algoritmo certo (Personalized PageRank) pode ser uma solução extremamente poderosa, eficiente e escalável.
Ele prova que nem todo problema de grafos precisa da solução mais complexa. Às vezes, a solução mais elegante já existe há décadas, esperando a engenharia correta para ser aplicada em escala planetária.
Referências
- Gupta, A., Goel, A., Lin, J., Sharma, A., Wang, D., & Zadeh, R. (2013). WTF: The Who to Follow Service at Twitter. Proceedings of the 22nd International Conference on World Wide Web (WWW).
- Haveliwala, T. H. (2002). Topic-sensitive PageRank. Proceedings of the 11th International Conference on World Wide Web (WWW). (Paper seminal sobre a ideia de PageRank Personalizado).
Sobre o autor
Rener Menezes
Cofundador & CTO — FitBank
Rener Menezes é cofundador e CTO do FitBank, fintech brasileira de Banking-as-a-Service. Com mais de 25 anos de experiência projetando sistemas financeiros em larga escala, é bacharel em Sistemas de Informação e mestrando na Unifor, onde pesquisa Redes Neurais de Grafos e aprendizado por reforço para detecção de fraude. Interesses: sistemas distribuídos, infraestrutura de pagamentos e graph ML.
Links: LinkedIn · ORCID · contato@grafolab.ia.br


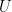




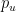

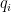

















![\displaystyle s(q,d) = \lambda \cos(q,d) + (1-\lambda) g(d), \quad \lambda \in [0,1].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+s%28q%2Cd%29+%3D+%5Clambda+%5Ccos%28q%2Cd%29+%2B+%281-%5Clambda%29+g%28d%29%2C+%5Cquad+%5Clambda+%5Cin+%5B0%2C1%5D.&bg=ffffff&fg=000&s=0&c=20201002)




