Resumo — Arquiteturas de microserviços são poderosas, mas complexas. Uma falha em um serviço pode derrubar dezenas de outros. E se pudéssemos prever novas interações problemáticas antes que elas causem incidentes? Uma pesquisa recente (aceita no ICPE 2025) explora o uso de Graph Neural Networks (GNNs), especificamente a Graph Attention Network (GAT), para modelar o call graph (grafo de chamadas) e prever futuras conexões. Os resultados mostram alta precisão, abrindo caminho para um monitoramento mais proativo.
1. O Problema: A Teia Complexa dos Microserviços
Microserviços trouxeram agilidade, mas também uma complexidade explosiva. Em vez de um monólito, temos centenas (ou milhares) de pequenos serviços conversando entre si. Entender quem chama quem, quando e por quê, é o trabalho da observabilidade.
Ferramentas de tracing (como Jaeger ou Zipkin) nos dão a matéria-prima: os registros de cada chamada. A partir deles, podemos construir o Call Graph: um grafo onde os nós são os serviços e as arestas são as chamadas entre eles.
Mas analisar o passado não é suficiente. Queremos prever o futuro. E se pudéssemos saber que o serviço A está prestes a começar a chamar o serviço B (uma interação nova e talvez inesperada)? Isso permitiria:
- Alertas Proativos: “Atenção: padrão de chamada incomum detectado!”
- Prevenção de Falhas em Cascata: Identificar dependências críticas antes que elas causem um apagão.
- Otimização de Recursos: Alocar capacidade (autoscaling) de forma mais inteligente.
O desafio é: como prever essas futuras arestas em um grafo que muda constantemente?
2. A Solução: GNNs no Grafo de Chamadas Temporal
A pesquisa que discutimos aqui propõe modelar o call graph não como uma foto estática, mas como uma sequência de “filmes” (snapshots temporais) e usar GNNs para aprender a dinâmica dessas interações.
A Modelagem:
- Nós: Cada microserviço/serviço.
- Arestas: Chamadas entre serviços, direcionadas (
A -> B). Crucialmente, as arestas são segmentadas por janelas de tempo (ex: snapshots a cada 5 minutos). - Tarefa: Link Prediction Temporal. Dado o estado do grafo até o tempo
t, prever quais arestas (chamadas) existirão na janelat + Δt.
3. Por Que GNNs? E Por Que GAT Especificamente?
As GNNs são uma escolha natural porque elas aprendem a partir da estrutura do grafo. O embedding (representação) de um serviço é influenciado pelos serviços que ele chama e pelos que o chamam.
Mas por que a Graph Attention Network (GAT)? O call graph de microserviços é dinâmico e barulhento:
- O volume de chamadas entre dois serviços pode variar drasticamente.
- Novos serviços surgem, outros morrem.
- Alguns serviços são “hubs” (chamados por muitos), outros são mais isolados.
A GAT usa um mecanismo de atenção. Ao calcular o embedding do serviço A, ela não trata todos os seus vizinhos (quem A chama ou quem chama A) da mesma forma. Ela aprende a dar pesos diferentes a cada vizinho, focando nos mais “informativos” para prever o comportamento futuro de A. A hipótese é que essa capacidade de “focar no que importa” torna a GAT mais robusta a ruídos e mudanças no padrão de tráfego.
4. O Pipeline (Alto Nível)
O fluxo de trabalho proposto no paper segue passos lógicos:
- Coleta de Dados: Obter traces de chamadas de um sistema de observabilidade.
- Construção do Grafo Temporal: Processar os traces para criar os snapshots do call graph (ex: um grafo a cada 5 minutos).
- Amostragem Negativa: Para treinar um modelo de link prediction, precisamos de exemplos de “não-links”. Mas não podemos simplesmente escolher pares aleatórios. O paper usa técnicas para criar “negativos difíceis” – pares de serviços que não se chamaram, mas que poderiam plausivelmente se chamar (ex: estão “próximos” no grafo).
- Treinamento da GAT: Treinar o modelo GAT em janelas passadas para prever as arestas na janela seguinte.
- Avaliação Temporal: Testar o modelo em janelas futuras, usando métricas como AUC, Precision, Recall e F1-Score.
5. Resultados e Implicações: Previsão é Possível!
O estudo (aceito no ICPE 2025) reportou resultados promissores em dados reais, alcançando altos valores de AUC, Precision, Recall e F1-Score. Isso sugere que é viável usar GNNs para prever, com razoável antecedência, novas interações entre microserviços.
As implicações práticas são significativas:
- Monitoramento Adaptativo: Em vez de alertas baseados em regras fixas, podemos ter alertas baseados em previsões de comportamento anômalo.
- Prevenção de Incidentes: Se o modelo prevê uma nova chamada de
A -> Bque sobrecarregariaB, a equipe de SRE pode intervir antes do incidente. - Planejamento de Capacidade: Usar as previsões para ajustar o autoscaling de forma mais proativa.
6. Desafios e Limitações (O que o GAT “Erra” ou Onde a Estrada é Longa)
A pesquisa é promissora, mas o caminho para a produção tem desafios (alguns discutidos no paper, outros práticos):
- Generalização: O modelo funcionará em diferentes arquiteturas de microserviços e stacks de observabilidade?
- Custo Computacional: Calcular features temporais e rodar GNNs pode ser caro. A inferência precisa ser rápida o suficiente para ser útil.
- Comparação com Baselines: Como a GAT se compara a abordagens mais simples (como Adamic-Adar no grafo temporal) ou outras GNNs (como GraphSAGE ou GNNs Temporais específicas)? É crucial ter baselines fortes.
- Interpretabilidade: Por que o modelo previu a chamada
A -> B? Entender a causa raiz é fundamental para a ação.
O título “o que o GAT acerta (e erra)” não significa que a GAT seja ruim, mas sim que, como toda ferramenta, ela tem um ponto ideal de aplicação e enfrenta desafios práticos na implementação real.
Conclusão
Modelar o call graph de microserviços como um grafo dinâmico e aplicar GNNs (como a GAT) abre uma nova fronteira para a observabilidade e o monitoramento proativo. A capacidade de prever futuras interações, mesmo com desafios em aberto, é um passo promissor para construir sistemas distribuídos mais resilientes e eficientes.
Referência Principal (O Artigo)
- Khodabandeh, G.; Ezaz, A.; Babaei, M.; Ezzati-Jivan, N. (2025). Utilizing Graph Neural Networks for Effective Link Prediction in Microservice Architectures. arXiv preprint arXiv:2501.15019. Aceito para publicação no Proceedings of the ACM/SPEC International Conference on Performance Engineering (ICPE), 2025. [arXiv:2501.15019]
Referências Fundacionais
- Veličković, P. et al. (2018). Graph Attention Networks (GAT). ICLR 2018.
Sobre o autor
Rener Menezes
Cofundador & CTO — FitBank
Rener Menezes é cofundador e CTO do FitBank, fintech brasileira de Banking-as-a-Service. Com mais de 25 anos de experiência projetando sistemas financeiros em larga escala, é bacharel em Sistemas de Informação e mestrando na Unifor, onde pesquisa Redes Neurais de Grafos e aprendizado por reforço para detecção de fraude. Interesses: sistemas distribuídos, infraestrutura de pagamentos e graph ML.
Links: LinkedIn · ORCID · contato@grafolab.ia.br

 Validação
Validação 

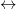
 ): A Modularidade tem um “limite de resolução”: ela naturalmente favorece comunidades de um certo tamanho e pode “esconder” comunidades menores, mesmo que sejam óbvias. Para contornar isso, usamos um parâmetro de resolução (
): A Modularidade tem um “limite de resolução”: ela naturalmente favorece comunidades de um certo tamanho e pode “esconder” comunidades menores, mesmo que sejam óbvias. Para contornar isso, usamos um parâmetro de resolução (
 : Diminui o “zoom”. Encontra comunidades maiores e mais abrangentes. Escolher o
: Diminui o “zoom”. Encontra comunidades maiores e mais abrangentes. Escolher o 

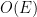
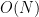 `, dependendo da representação).
`, dependendo da representação).