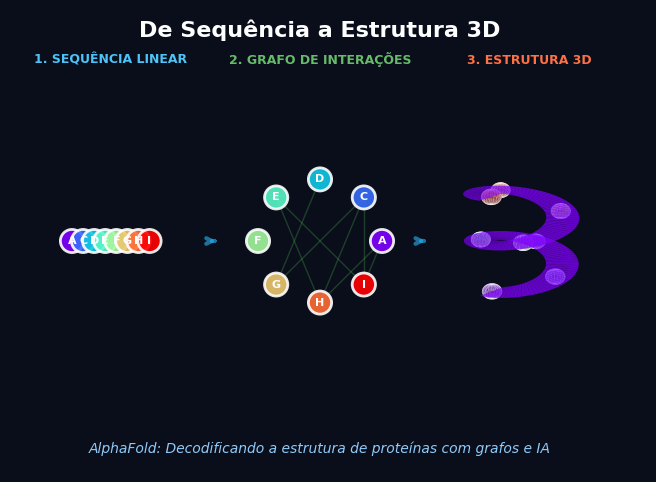

Resumo — Por 50 anos, o “problema do dobramento de proteínas” foi um dos grandes desafios abertos da biologia. Como prever a forma 3D de uma proteína apenas olhando para sua sequência linear de aminoácidos? A resposta veio com o AlphaFold, da DeepMind. O que poucos notam é que o segredo por trás dessa revolução é a modelagem da proteína como um grafo geométrico, onde aminoácidos são nós e suas interações espaciais são arestas. Este post explora como a biologia molecular se tornou um problema de aprendizado em grafo.
1. O Enigma: De uma Linha para uma Máquina 3D
Imagine que você tem um barbante com centenas de nós coloridos. Se você soltar esse barbante, ele se enrolará em um emaranhado específico. Na biologia, esse barbante é a proteína: uma cadeia linear de aminoácidos (representados por letras como A, C, D, E).
O problema é que a função da proteína (se ela carrega oxigênio, combate vírus ou digere açúcar) depende exclusivamente da sua forma tridimensional final.
Prever essa forma 3D apenas a partir da sequência linear de letras (1D) era considerado quase impossível. A cada dois anos, a competição global CASP (Critical Assessment of Protein Structure Prediction) desafiava cientistas a resolverem isso. Por décadas, o progresso foi lento. Até a chegada das redes neurais profundas e, especificamente, da modelagem baseada em grafos.
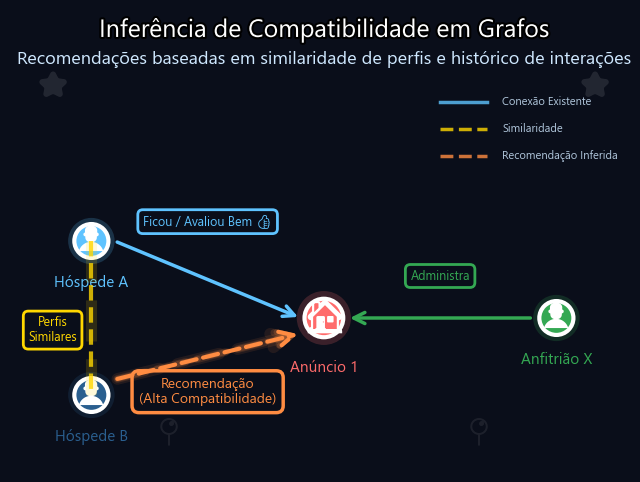
2. A Ideia Central: A Proteína é um Grafo
Para resolver o problema, o AlphaFold mudou a perspectiva. Em vez de tratar a proteína apenas como uma sequência (como um texto em NLP) ou uma imagem (como em Visão Computacional), ele a trata como um grafo.
- Nós (Resíduos): Cada aminoácido da sequência é um nó no grafo.
- Arestas (Interações): As conexões entre os nós representam a proximidade espacial ou a relação evolutiva entre eles.
Mesmo que dois aminoácidos estejam muito distantes na sequência linear (ex: posição 10 e posição 300), eles podem estar “grudados” um no outro quando a proteína se dobra em 3D. No grafo, isso é representado por uma aresta. O objetivo do modelo é, essencialmente, prever a estrutura desse grafo e as distâncias exatas dessas arestas.
3. Por Dentro do AlphaFold: O Bloco Evoformer
A arquitetura do AlphaFold 2 é complexa, mas seu coração reside em um componente chamado Evoformer. Ele processa duas “visões” do problema simultaneamente:
- Representação MSA (Multiple Sequence Alignment): Olha para a história evolutiva da proteína (como ela mudou ao longo de milhões de anos).
- Representação de Pares (O Grafo): Esta é a matriz de adjacência do grafo. Ela modela a relação entre cada par de aminoácidos (


O modelo funciona trocando informações entre essas duas visões. É um mecanismo híbrido que mistura a atenção dos Transformers com a troca de mensagens das GNNs (Graph Neural Networks).
O modelo “raciocina” sobre o grafo: “Se o aminoácido A e o B evoluíram juntos, eles provavelmente estão fisicamente conectados (têm uma aresta). Se A está perto de B, e B está perto de C, onde está A em relação a C?” (Isso é a desigualdade triangular, uma propriedade geométrica que o modelo aprende a respeitar).
4. Geometric Deep Learning: O Novo Paradigma
O AlphaFold é o exemplo mais famoso de uma área emergente chamada Geometric Deep Learning.
Diferente de redes sociais, onde a posição dos nós é abstrata, em proteínas a geometria importa.
- Cada nó tem atributos físico-químicos (carga, tamanho).
- Cada aresta tem propriedades geométricas reais: distância (Angstroms) e ângulo.
O AlphaFold aprende a inferir esse grafo tridimensional dinâmico. Ele começa com um grafo implícito (a sequência) e, camada por camada, refina as posições e arestas até que a estrutura 3D final emerja.
5. Resultados e Impacto Histórico
No CASP14 (2020), o AlphaFold 2 chocou a comunidade científica. Ele atingiu uma pontuação de precisão (GDT_TS) de 92.4, um nível considerado comparável a métodos experimentais caros e demorados (como cristalografia de raios-X). A diferença para o segundo colocado foi de quase 30 pontos percentuais.
Desde então, a DeepMind liberou o código e um banco de dados com mais de 200 milhões de estruturas previstas — cobrindo quase todo o catálogo biológico conhecido. O que antes levava anos de doutorado para descobrir (a estrutura de uma única proteína), agora é acessível em segundos.
Conclusão
O caso do AlphaFold expande nossa visão sobre o que é um “problema de grafo”. Ele prova que grafos não servem apenas para modelar redes sociais ou transações financeiras; eles são a linguagem natural para descrever a estrutura da matéria viva. Ao combinar a intuição biológica com arquiteturas de Graph Learning e Transformers, o AlphaFold não apenas resolveu um quebra-cabeça de 50 anos, mas inaugurou uma nova era para a biologia digital e o design de fármacos.
Referências
- Jumper, J. et al. (2021). Highly accurate protein structure prediction with AlphaFold. Nature, 596, 583–589.
- Senior, A. W. et al. (2020). Improved protein structure prediction using potentials from deep learning. Nature, 577, 706–710.
- Bronstein, M. M. et al. (2021). Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges. arXiv:2104.13478. (Um survey fundamental sobre o conceito de Deep Learning Geométrico).
- AlphaFold Protein Structure Database (EMBL-EBI).
Sobre o autor
Rener Menezes
Cofundador & CTO — FitBank
Rener Menezes é cofundador e CTO do FitBank, fintech brasileira de Banking-as-a-Service. Com mais de 25 anos de experiência projetando sistemas financeiros em larga escala, é bacharel em Sistemas de Informação e mestrando na Unifor, onde pesquisa Redes Neurais de Grafos e aprendizado por reforço para detecção de fraude. Interesses: sistemas distribuídos, infraestrutura de pagamentos e graph ML.
Links: LinkedIn · ORCID · contato@grafolab.ia.br

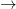

 ) é uma versão mais inteligente e muito mais rápida para mapas. Ele combina o custo do Dijkstra (o tempo que você já gastou) com uma heurística: uma estimativa “otimista” do tempo restante (ex: a distância em linha reta até o destino dividida pela velocidade máxima da via). Essa heurística “puxa” a busca na direção correta, fazendo com que o algoritmo explore muito menos nós desnecessários.
) é uma versão mais inteligente e muito mais rápida para mapas. Ele combina o custo do Dijkstra (o tempo que você já gastou) com uma heurística: uma estimativa “otimista” do tempo restante (ex: a distância em linha reta até o destino dividida pela velocidade máxima da via). Essa heurística “puxa” a busca na direção correta, fazendo com que o algoritmo explore muito menos nós desnecessários.






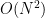 ), o que é proibitivo para grafos grandes. Por isso, muitas arquiteturas de Graph Transformer usam:
), o que é proibitivo para grafos grandes. Por isso, muitas arquiteturas de Graph Transformer usam:
